I've been using KiCAD as my PCB design tool of choice for years, and as my designs grew in complexity I began using Sonnet for EM field simulation prior to manufacturing boards.
Unfortunately, interoperability between these tools was less than ideal.
KiCAD export formats
Gerber/Excellon: Stable and reliable
DXF: Generates one file per layer. Drill hits can be plotted as Xs, but there's no obvious way to plot hole boundaries. Seems to sometimes generate polygons which are not closed (missing the last vertex).
Sonnet import formats
DXF: Standard feature with all (paid) Sonnet editions. Expects one file, with a separate pen type for each conductor or drill layer. Minimal tolerance to malformed files.
GDSII: Extra-cost option, but reasonably priced (about 25% of the cost of L2 Basic)
Gerber/Excellon: Extra-cost option, absurdly priced (five digits). Only runs on Windows, not available in the Linux edition at all. Apparently this is because it's a third-party conversion tool they license as a binary, so they have no ability to port it or offer less extravagant pricing.
I spent a while tinkering and came up with a flow using KLayout that seems to work well, so I thought I'd do a quick writeup so other folks could benefit from it. This might be of interest to users of other PCB CAD tools as well. Although KLayout is nominally an IC mask layout editor, it can also read Gerber!
Step 1: Gerber generation
Nothing special here. Export your gerbers just like you would for manufacturing a board.
Step 2: KLayout import
Launch KLayout and select File | Import | Gerber PCB | New Project - Free Layer Mapping. Specify the location of the exported gerbers.
On the next page, if asked to automatically populate the project, say "no". Answering yes will result in all of your soldermask, silkscreen, etc files being imported as well, which you probably don't want.
Click the plus sign button in the top right of the dialog and select all of the copper and drill layers of interest for your simulation.
On the next page, you should see one GDS layer generated for each of the files you're importing. There's no need to touch any settings.
On the next page, map gerber files to GDS layer IDs in a logical order. I suggest top to bottom with blind/buried vias in sequence and through-board vias at the end. Each gerber file should be mapped to exactly one GDS layer.
Leave all settings on the next page as default.
On the next page, make sure the database unit is 1.0 micron. Coordinates are rounded to multiples of the database unit internally, so it needs to be small enough to avoid round-off errors. Microns are the most convenient unit to use with Sonnet's DXF importer.
Check the "merge polygons" box. This flattens all overlapping polygons, which is important because KiCAD likes to generate extra gerber flashes in vias and zone fills.
While not merging, or merging in Sonnet, will ultimately produce the same simulation result, Sonnet's geometry editor (xgeom) gets really slow if your geometry has too many polygons. Flattening before Sonnet sees the board avoids this.
Now the gerber conversion is done! Click "import" and you should see the PCB in the KLayout editor view.
Step 3: KLayout export
Select File | Save As. Choose file type DXF and pick a file name. Select "no compression", scaling factor 1.0, database unit 1 micron, and polygons as POLYLINE.
Step 4: Sonnet import
Create a new, empty Sonnet project and configure your desired stackup so that all layers and metal types are available for import. Select File | Import | DXF and choose the generated DXF file.
Choose "Import using present project as template".
On the next page, enter the layer mappings you selected in KLayout.
On the next page, select units as microns.
For the remainder of the Sonnet import wizard, enter settings as appropriate for your design. Converting vias to rectangular greatly reduces memory requirements for simulation and is normally OK as long as the vias are electrically small.
If you have large via fences, coplanar waveguides, or similar, the "simplify via arrays" option may be of use as well. This one needs to be used with caution because it sometimes merges more vias than desired. I generally prefer to import individual vias and merge manually to avoid unexpected results.
Over the years I've grown to have quite the collection of RF cables in my lab, some with better datasheets than others. But how good were they really? I decided to fire up the VNA and collect some data to see how a few of them really performed.
Experimental setup:
Data was collected on a Pico Technology PicoVNA 106 with current traceable calibration, at a controlled 21C ambient temperature with 45% RH.
SOLT user calibration was performed immediately before data collection.
All SMA connections were torqued to 5 lbf-in.
SMA female-female couplers were used between the VNA cables and the DUT cables. These were not de-embedded as I don't have a VNA cal kit with SMA male terminations.
All cables were SMA male at both ends. If available, I tested two identical cables of each type to see how well matched they were.
4001 S-parameter points were collected at even intervals from 10 MHz to 6 GHz. I used Sonnet's S-parameter viewer for analysis of the collected data,
Results were mostly as expected - longer cables had higher loss, and higher quality cables had lower. I was a little disappointed to find that the Crystek semi-rigid cable didn't outperform the Mini-Circuits, though.
S21 of cables under test
After normalizing to cable length, results were:
Mini-Circuits .086: 0.71 dB/foot
Crystek Microwave .086: 0.76 dB/foot
CD International RG-188: 0.78 dB/foot
CD International RG-174: 1 dB/foot
Return Loss
Better quality cable assemblies definitely won here.
S11 of cables under test
It's a bit hard to see since the graph is so busy, but the CD International cables (red, blue, black) had consistently higher return loss than the Crystek (pink, cyan) and Mini-circuits (green).
The CD International RG188 cable got as high as -17 dB S11 at 4.77 GHz. The worst Crystek cable hit -25.1 dB at 2.63 GHz, and the worst Mini-Circuits cable hit -25.4 dB at 1.51 GHz.
Propagation Velocity
Nothing too surprising here.
Group delay of cables under test
Everything was pretty flat, and longer cables had longer delay. Calculated propagation velocities (assuming all cables were exactly the nominal length):
Crystek .086: 1.68 ns/foot (0.61 C)
Mini-Circuits .086: 1.53 ns/foot (0.66 C)
CD International RG-188: 1.49 ns/foot (0.68 C)
CD International RG-174: 1.60 ns/foot (0.64 C)
Phase Matching
For the cables I tested two of, I zoomed in to compare how tightly the propagation delays were matched.
Most of these measurements are a bit noisy because I'm pushing limits of phase resolution on my VNA.
CD International, 3 foot RG-174. Looks like one is about 50ps shorter?
CD International, 3-foot RG188. Can't see any skew at all.
Crystek Microwave 1-foot .086. Maybe 50ps of skew?
Mini-Circuits 2-foot flex .086. No observable skew.
Conclusions
There's a few takeaways from this little experiment.
First, at the speeds I currently work at, there appears to be no need to worry about buying expensive phase-matched cables. While different types of coax had significant skew between equal-length cable assemblies, skew between two units of the same SKU ranged from "at the edge of my ability to measure" to entirely undetectable.
Given that my oscilloscopes sample at 20 Gsps when not doing channel interleaving, the maximum skew between any of the identical cables tested would result in a single sample of phase error. This shouldn't be enough to cause problems with my measurements.
Second, all of my cables have non-negligible loss. Even the high-quality Mini-Circuits cables have 0.8 dB of loss at the 2 GHz bandwidth limit of my current flagship scope, and 1.1 dB at the 4 GHz bandwidth limit of the new one I have on the way. I'm definitely going to start thinking more seriously about de-embedding cables from my measurements moving forward.
It's been two years but I'm back! I've had a lot going on and have been way too busy to post about it, but here's a sneak peek...
Long story short, I bought a house with my wife and have been renovating it into the lab of my dreams. When complete, it will have a dedicated wet chemistry bench, 400 square feet of ESD-floored lab space, 200 square feet of office/conference room space, over a mile of multimode fiber and copper Ethernet cabling, and lots of other goodies. There will be a post (or more likely a series) on the setup when it's done, but that's still a few months out.
Among the new toys I've acquired is a LeCroy WaveRunner 8104 oscilloscope - a beast of a scope with four 1 GHz channels at up to 20 Gsps.
New scope is on the right rack (left side scope is an older WaveSurfer 3034)
There's just one problem... probes.
The stock passive probes have a rated bandwidth of 500 MHz and, as with all passive R-C probes, have severe input impedance roll-off at higher frequencies. According to the datasheet, at ~150 MHz the input impedance drops below 100Ω and it only gets worse from there! As you might imagine, this isn't going to be healthy for signals on a 50Ω line.
LeCroy does sell active probes (such as the ZS1500) but they are not cheap - even secondhand, you're looking at a low four-figure price tag per channel. I might pick one up for comparison purposes eventually, but won't be evaluating them during this post.
In order to explore different probe designs, I built a characterization board on OSHPark's 4-layer process. It has an edge-launch SMA at either end of two 50Ω microstrip traces, a ground plane on layer 2, then the bottom layers are unused. (I could have done this as a 2-layer board, but the traces would have been massive given the increased distance to the ground plane.)
Probe characterization board. The little gold points and the clip are grounds.
The test board has two sets of microstrips to allow A/B comparison, or passing differential signals through the test setup. They had to be pretty far apart due to mechanical constraints of the SMA connectors, and I elected to route the signals loosely coupled to avoid unwanted parasitics during single-ended tests.
I didn't even bother testing the standard alligator-clip ground wires on the PP022 probes, because I knew these were way too inductive to be of any value whatsoever for high-speed signals. Plus, to make it a fair comparison I needed to give the stock probe a chance to put its best foot forward. All of this testing was done with the spring-tip ground.
The first test signal was a 1 GHz pure sine source built around a Crystek CCSO-914X-1000 oscillator with some additional filtering on the output to remove harmonics.
Test setup. The helping-hand is sitting on top of the coax leading to my scope so it doesn't flail around.
Closeup of the probe tip
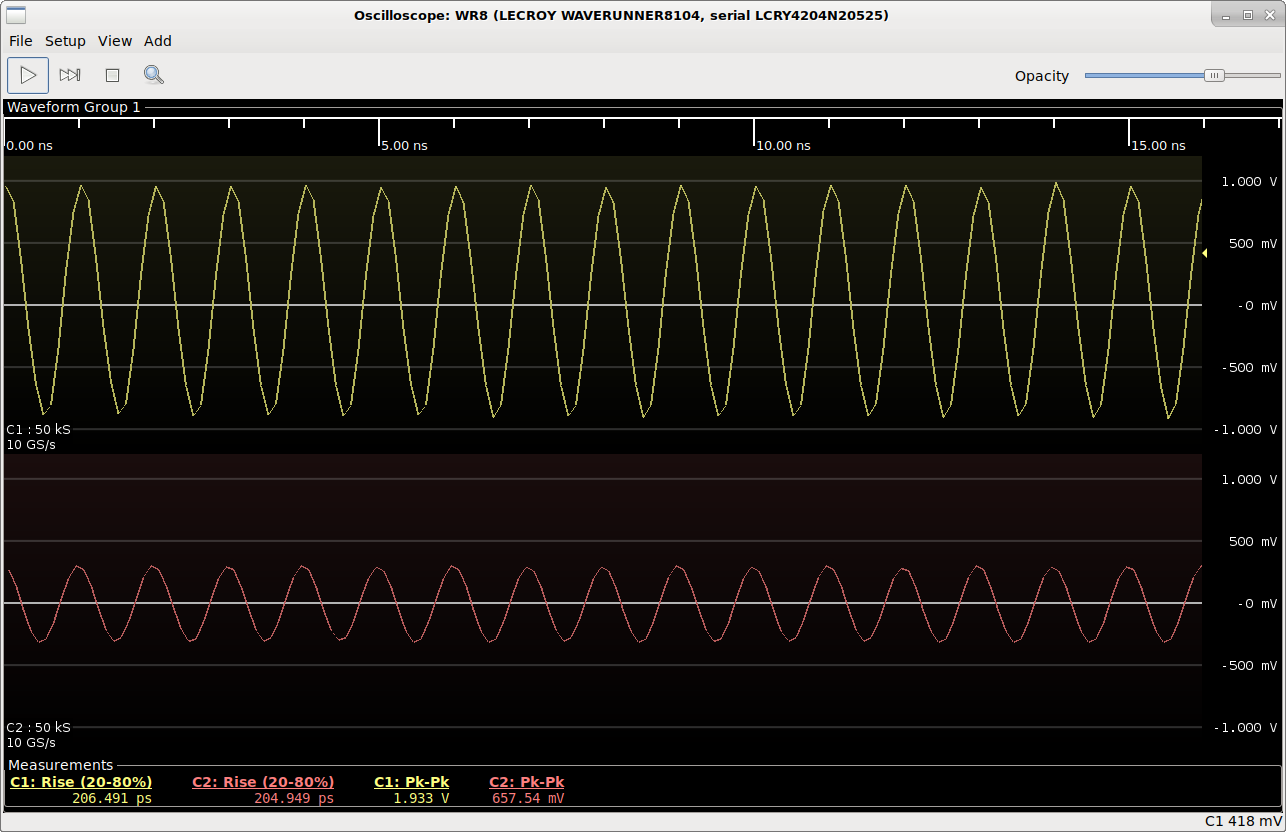
Unsurprisingly, the signal was severely attenuated since it was well past the bandwidth limit of the probe. The peak-to-peak voltage measured via the SMA feed-through was 1930 mV while the PP022's output read 657 mV, or about -9.4 dB of insertion loss. The probe also loaded the signal down noticeably; when the probe was removed the SMA feed-through signal read 2192 mV.
SMA feedthrough (top) vs PP022 (bottom), same scale. I probably should have turned persistence on to smooth out the traces, but the amplitude difference is strikingly obvious.
All screenshots were gathered using the "glscopeclient" software I've been writing over the past few months. There will be a separate post about it once I've done a bit more testing and development.
The other probe being tested today was a custom 20:1 transmission line probe. I had high hopes for this design as I had used it with good results on slower circuits in the past, but this was my first time trying it on such fast signals.
Transmission line probe prototype
This probe has a nominal 1KΩ impedance at DC and should roll off fairly slowly, since it has a largely resistive input stage (953Ω into a 50Ω line). At frequencies in the GHz range the resistor begins to become slightly capacitive, although inductive parasitics are probably still negligible if the models I've looked at are accurate.
The test setup was pretty much the same as before, except I used the helping hands to hold the probe. (I have a 3D printed shell on order that fits the same Pico Tech probe positioners I used on the PP020, but it's not here yet.)
Experimental setup
At first glance, performance was quite encouraging. The loading was noticeably less (feed-through signal was 2003 mV, vs 2192 un-loaded and 1930 with the stock probe) and the measured signal amplitude was 946 mV, very close to the actual value. This suggests the experimental probe design has a -3 dB bandwidth right around 1 GHz, or double the bandwidth of the stock probe!
Feedthrough signal (top), prototype probe (bottom)
The obvious next step was to try a more aggressive test. I threw up a quick test bitstream for my AC701 board that generated a 1.25 Gbps SGMII/1000base-X idle sequence (8B/10B codes K28.5 D16.2 repeating forever).
The experimental setup was identical to before, except that both legs of the test board were used since the GTP transceiver has a differential output. Although I was only probing one leg, I wanted to run clock recovery off the differential signal to minimize jitter in my measurements.
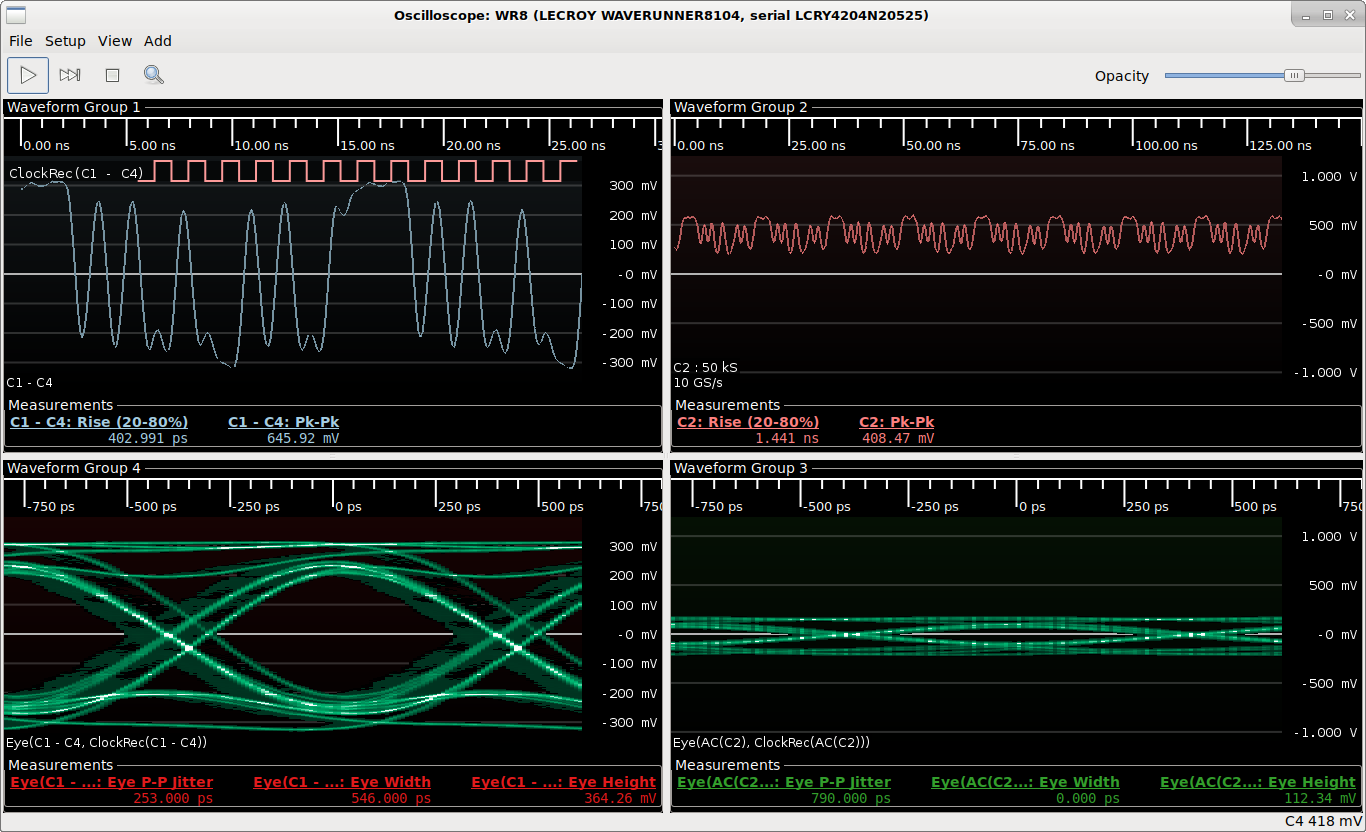
The positive leg of the feed-through differential pair was plotted in the top left quadrant of the scope view, while the probe's output was plotted in the top right. An offscreen filter subtracted the two differential pair legs, then fed the differential signal to a CDR PLL. This same recovered clock was used as the clock source for eye patterns on both signals, displayed in the bottom quadrants below their corresponding inputs.
The PP020 performed surprisingly well.
SMA feedthrough (left), PP020 (right)
Although it did noticeably degrade the feed-through signal, and the eye
was attenuated to oblivion (with a mere 110 mV opening), the individual bits were
still (barely) visible in the waveform display. Not bad for gigabit data on a 500 MHz probe!
This failure was entirely expected - but what I did not expect was how poorly my own probe design performed on the same test signal. While it was less intrusive to the pass-through signal, the eye measured through the probe was practically nonexistent.
SMA feedthrough (left), my probe (right)
Something was clearly not right, but the eye was so garbled I had a hard time seeing exactly what. I recompiled the FPGA bitstream to send a much slower, and more repetitive, test pattern - 0xFF00 at the same 1.25 Gbps rate. This is equivalent to a 156.25 Mbps 1-0-1-0 pattern, or a 78.125 MHz squarewave.
With no probe, the signal looked quite nice. There was a small amount of ringing on the rising edge, but this didn't impair readability of the signal at all. I also tried another color ramp (matplotlib Viridis) for the eye patterns in hopes of seeing more detail.
Differential signal with no probe
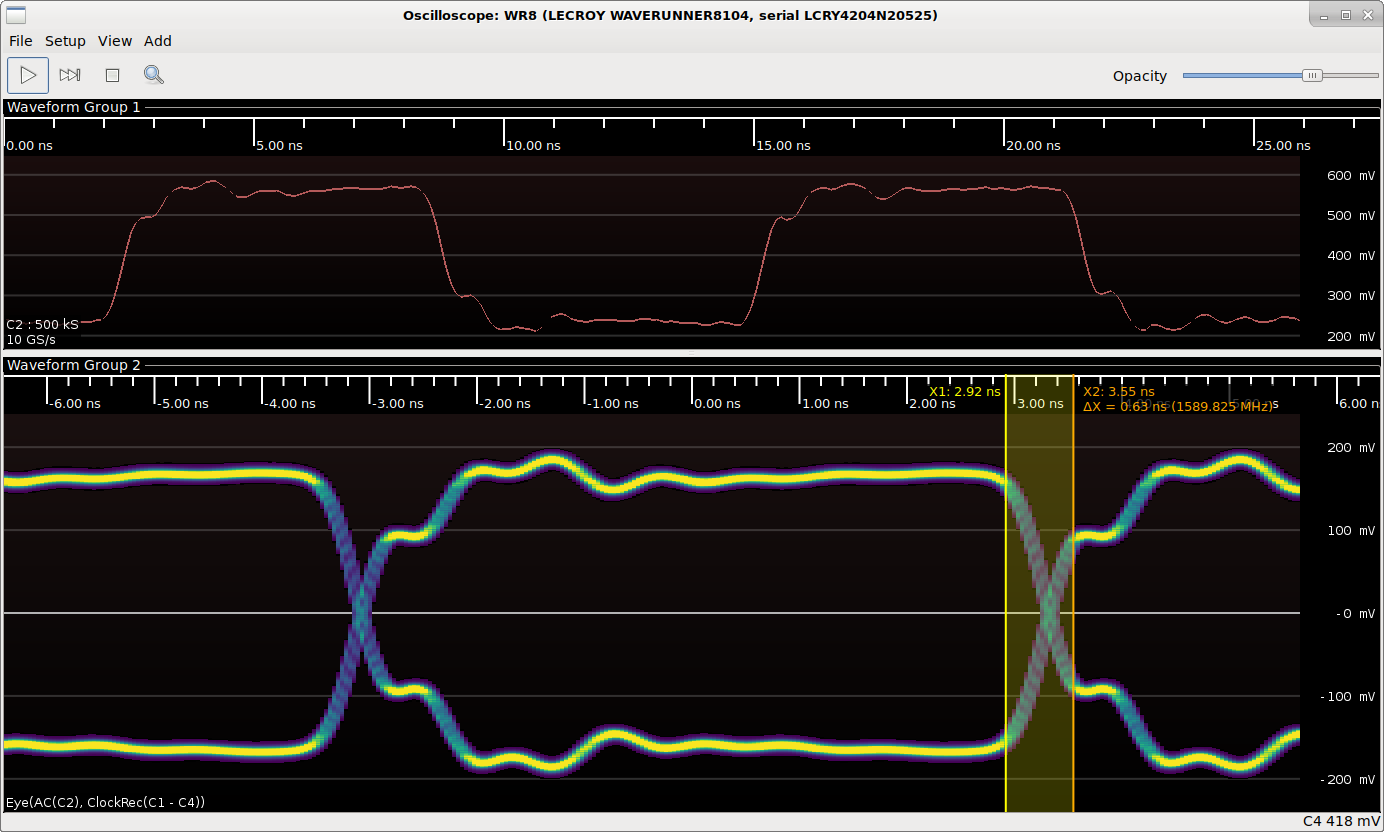
With my probe, the results were less impressive. There was a noticeable step on the rising edge followed by what looked like a spike above the nominal voltage, followed by the same ringing present in the original signal.
My probe at 125.25 Mbps
By treating the rising edge as a TDR impulse and comparing amplitude to the final value, we can determine that the initial rising edge reaches an impedance of about 38Ω for ~600 ps, then 55Ω for a bit over 1000 ps, then stabilizes to its final value (the 50Ω termination at the scope). Given that the scope only has 1 GHz bandwidth I'm not entirely sure how accurate this data is, but it's all I had to go on.
The obvious hypothesis was that the 38Ω area was an impedance mismatch at either the probe needle or the MMCX connector. I discounted the needle as the mismatch initially, because an 0.51mm diameter needle shank 2mm from a ground lead has an impedance of 244Ω which didn't match the observed data whatsoever.
The next obvious target was the MMCX. I calculated 26Ω impedance for the 1.1mm wide center contact over the ground plane (I had somehow forgotten to put a ground cutout under it). After milling out a cavity, though, performance didn't seem to improve by any detectable amount.
Milled cavity under center pad
Without a 3D field solver, I have no way of knowing if this cavity was large enough. I might try and make it bigger at some point.
The other possibility is that the lack of a cutout under the needle is problematic. I initially thought this would be OK because the needle is about the same diameter (0.51mm vs 0.41mm) as the PCB trace, but later calculations for an 0.51mm wire above a ground plane using the OSHPark stackup suggest that the impedance of the needle mounting could be as low as 30-40Ω which is consistent with the observed impedance hump.
Finally, the 0.41mm microstrip appears to have been over-etched closer to 0.32mm. If the needle mounting is the impedance mismatch, this would be consistent with the observed 55Ω hump after it. I might try thickening the microstrip with solder to see if this helps bring impedance up closer to 50.
For those of you who aren't keeping up with my occasional Twitter/Facebook posts on the subject, I volunteer with a local search and rescue unit. This means that a few times a month I have to grab my gear and run out into the woods on zero notice to find an injured hiker, locate an elderly person with Alzheimer's, or whatever the emergency du jour is.
Since I don't have time to grab fresh food on my way out the door when duty calls, I keep my pack and load-bearing vest stocked with shelf-stable foods like energy bars and surplus military rations. Many missions are short and intense, leaving me no time to eat anything but finger-food items (Clif bars and First Strike Ration sandwiches are my favorites) kept in a vest pocket.
My SAR vest. Weighs about 17 pounds / 7.7 kg once the Camelbak bladder is added.
On the other hand, during longer missions there may be opportunities to make hot food while waiting for a medevac helicopter, ground team with stretcher, etc - and of course there's plenty of time to cook a hot dinner during training weekends. Besides being a convenience, hot food and drink helps us (and the subject) avoid hypothermia so it can be a literal life-saver.
I've been using MRE chemical heaters for this, because they're small, lightweight (20 g / 0.7 oz each), and not too pricey (about $1 each from surplus dealers). Their major flaw is that they don't get all that hot, so during cold weather it's hard to get your food more than lukewarm.
I've used many kinds of camp stoves (propane and white gas primarily) over the course of my camping, but didn't own one small enough to use for SAR. My full 48-hour gear loadout (including water) weighs around 45 pounds / 20 kg, and I really didn't want to add much more to this. The MSR Whisperlite, for example, weighs in at 430 g / 15.2 oz for the stove, fuel pump, and wind shield. Add to this 150 g / 5.25 oz for the fuel bottle, a pot to cook in, and the fuel itself and you're looking at close to 1 kg / 2 pounds all told.
I have an aluminum camp frying pan that, including lid, weighs 121 g / 4.3 oz. It seemed hard to get much lighter for something large enough that you could squeeze an MRE entree into, so I kept it.
After a bit of browsing in the local Wal-Mart, I found a tiny sheet metal folding stove that weighed 112 g / 3.98 oz empty. It's designed to burn pellets of hexamine fuel.
The stove. Ignore the aluminum foil, it was there from a previous experiment.
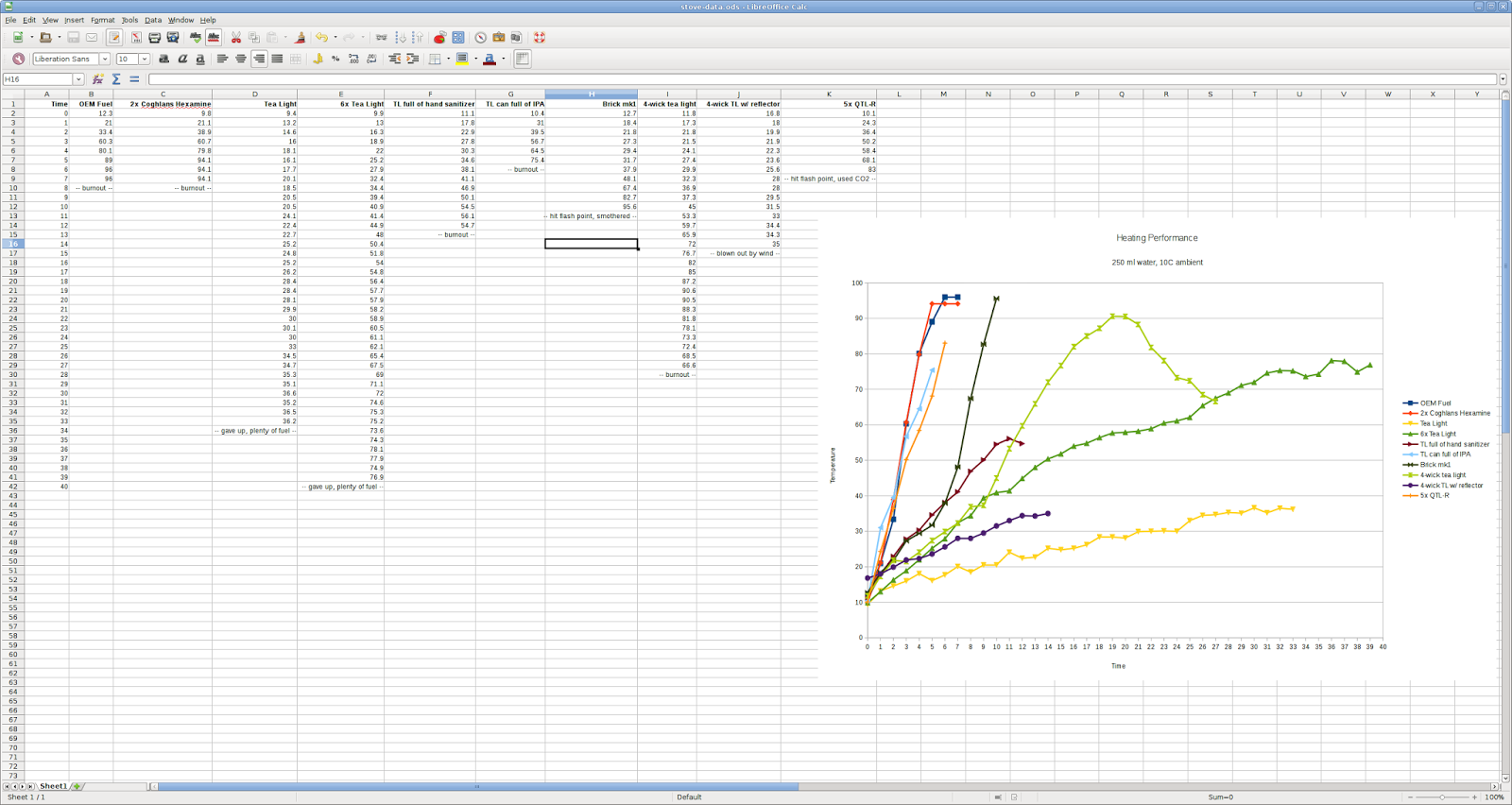
In my testing it worked pretty well. One pellet brought 250 ml of water from 10C to boiling in six minutes, and held it at a boil for a minute before burning out. The fuel burned fairly cleanly and didn't leave that much soot on the pot either, which was nice.
What's not so nice, however, was the fuel. According to the MSDS, hexamine decomposes upon heating or contact with skin into formaldehyde, which is toxic and carcinogenic. Combustion products include such tasty substances as hydrogen cyanide and ammonia. This really didn't seem like something that I wanted to handle, or burn, in close proximity to food! Thus began my quest for a safer alternative.
My first thought was to use tea light candles, since I already had a case of a hundred for use as fire starters. In my testing, one tea light was able to heat a pot of water from 10C to 30C in a whopping 21 minutes before starting to reach an equilibrium where the pot lost heat as fast as it gained it. I continued the test out to 34 minutes, at which point it was a toasty 36C.
The stove was big enough to fit more than one tea light, so the obvious next step was to put six of them in a 3x2 grid. This heated significantly more, at the 36-minute mark my water measured a respectable 78C.
I figured I was on the right track, but needed to burn more wax per unit time. Some rough calculations suggested that a brick of paraffin wax the size of the stove and about as thick as a tea light contained 1.5 kWh of energy, and would output about 35 W of heat per wick. Assuming 25% energy transfer efficiency, which seemed reasonable based on the temperature data I had measured earlier, I needed to put out around 675 W to bring my pot to a boil in ten minutes. This came out to approximately 20 candle wicks.
I started out by folding a tray out of heavy duty aluminum foil, and reinforcing it on the outside with aluminum foil duct tape. I then bought a pack of tea light wicks on Amazon and attached them to the tray with double-sided tape.
Giant 20-wicked candle before adding wax
I made a water bath on my hot plate and melted a bunch of tea lights in a beaker. I wasn't in the mood to get spattered with hot wax so I wore long-sleeved clothes and a face shield. I was pretty sure that the water bath wouldn't get anywhere near the ignition point of the wax but did the work outside on a concrete patio and had a CO2 fire extinguisher on standby just in case.
Melting wax. Safety first, everyone!
The resulting behemoth of a candle actually looked pretty nice!
20-wick, 700W thermal output candle with tea lights for scale
After I was done and the wax had solidified I put the candle in my stove and lit it off. It took a while to get started (a light breeze kept blowing out one wick or another and I used quite a few matches to get them all lit), but after a while I had a solid flame going. At the six-minute mark my water had reached 37C.
A few minutes later, disaster struck! The pool of molten wax reached the flash point and ignited across the whole surface. At this point I had a massive flame - my pot went from 48 to 82C in two minutes! This translates to 2.6 kW assuming 100% energy transfer efficiency, so actual power output was probably upwards of 5 kW.
I removed the pot (using welding gloves since the flames were licking up the handle) and grabbed a photo of the fireball before thinking about how to extinguish the fire.
Pretty sure this isn't what a stove is supposed to look like
Since I was outside on a non-flammable surface the fire wasn't an immediate safety hazard, but I wanted to put it out non-destructively to preserve evidence for failure analysis. I opted to smother it with a giant candle snuffer that I rapidly folded out of heavy-duty aluminum foil.
The carnage after the fire was extinguished. Note the discolored wax!
It took me a while to clean up the mess - the giant candle had turned tan from incomplete combustion. It had also sprung a leak at some point, spilling a bit of wax out onto my patio.
On top of that, my pot was coal-black from all of the soot the super-rich flame was putting out. My wife wouldn't let it anywhere near the sink so I scrubbed it as best I could in the bathtub, then spent probably 20 minutes scrubbing all of the gray stains off the tub itself.
In order to avoid the time-consuming casting of wax, my next test used a slug of wax from a tea light that I drilled holes in, then inserted four wicks. I covered the top of the candle with aluminum foil tape to reflect heat back up at the pot, in a bid to increase efficiency and keep the melt puddle below the flash point.
Quad-wick tea light
This performed pretty well in my test. It got my pot up to 35C at the 12-minute mark, which was right about where I expected based on the x1 and x6 candle tests, and didn't flash over.
The obvious next step was to make five of them and see if this would work any better. It ignited more easily than the "brick" candle, and reached 83C at the 6-minute mark. Before T+ 7 minutes, however, the glue on the tape had failed from the heat, and the wax flashed. By the time I got the pot out of harm's way the water was boiling and it was covered in soot (again).
This time, it was a little bit breezier and my snuffer failed to exclude enough air to extinguish the flames. I ended up having to blast it with the CO2 extinguisher I had ready for just this situation. It wasn't hard to put out and I only used about two of the ten pounds of gas. (Ironically, I had planned to take the extinguisher in to get serviced the next morning because it was almost due for annual preventive maintenance. I ended up needing a recharge too...)
After cleaning off my pot and stove, and scraping some of the spilled wax off my driveway, it was back to the drawing board. I thought about other potential fuels I had lying around, and several obvious options came to mind.
Testing booze for flammability
I'm not a big drinker but houseguests have resulted in me having a few bottles of liquor around so I tested it out. Jack didn't burn at all, Captain Morgan white rum burned fitfully and left a sugary residue without putting out much heat. 100-proof vodka left a bit of starchy residue and was tricky to light.
A tea light cup full of 99% isopropyl alcohol brought my pot to 75C in five minutes before burning out, but was filthy and left soot everywhere. Hand sanitizer (about 60% ethanol) burned cleanly, but slower and cooler due to the water content - peak temperature of 54C and 12 minute burn time.
Ethanol seemed like a viable fuel if I could get it up to a higher concentration. I wanted to avoid liquid fuels due to difficulty of handling and the risk of spills, but a thick gel that didn't spill easily looked like a good option.
After a bit of research I discovered that calcium acetate (a salt of acetic acid) was very soluble in water, but not in alcohols. When a saturated solution of it in water is added to an alcohol it forms a stiff gel, commonly referred to as a "California snowball" because it burns and has a consistency like wet snow. I don't have any photos of my test handy, but here's a video from somebody else that shows it off nicely.
Two tea light cups full of the stuff brought my pot of water to a boil in 8 minutes, and held it there until burning out just before the 13-minute mark. I also tried boiling a FSR sandwich packet in a half-inch or so of water, and it was deliciously warm by the end. This seemed like a pretty good fuel!
Testing the calcium acetate fuel. I put a lid on the pot after taking this pic.
I filled two film-canister type containers with the calcium acetate + ethanol gel fuel and left it in my SAR pack. As luck would have it, I spent the next day looking for a missing hiker so it spent quite a while bouncing around driving on dirt roads and hiking.
When I got home I was disappointed to see clear liquid inside the bag that my stove and fuel were stored in. I opened the canisters only to find a thin whitish liquid instead of a stiff gel.
It seemed that the calcium acetate gel was not very stable, and over time the calcium acetate particles would precipitate out and the solution would revert to a liquid state. This clearly would not do.
Hand sanitizer seemed like a pretty good fuel other than being underpowered and perfumed, so I went to the grocery store and started looking at ingredient lists. They all seemed pretty similar - ethanol, water, aloe and other moisturizers, perfumes, maybe colorants, and a thickener. The thickener was typically either hydroxyethyl cellulose or a carbomer.
A few minutes on Amazon turned up a bag of Carbomer 940, a polyvinyl carboxy polymer cross-linked with esters of pentaerythritol. It's supposed to produce a viscosity of 45,000 to 70,000 CPS when added to water at 0.5% by weight. I also ordered a second bottle of Reagent Alcohol (90% ethanol / 5% methanol / 5% isopropanol with no bittering agents, ketones, or non-volatile ingredients) since my other one was pretty low after the calcium acetate failure. Carbomer 940 is fairly acidic (pH 2.7 - 3.3 at 0.5% concentration) in its pure form and gel when neutral or alkaline, so it needs to be neutralized. The recommended base for alcohol-based gels was triethanolamine, so I picked up a bottle of that too.
Preparing to make carbomer-alcohol fuel gel
I made a 50% alcohol-water solution and added an 0.5% mass of carbomer. It didn't seem to fully dissolve, leaving a bunch of goopy chunks in the beaker.
Incompletely dissolved Carbomer 940 in 50/50 water/alcohol
I left it overnight to dissolve, blended it more, and then filtered off any big clumps with a coffee filter. I then added a few drops of triethanolamine, at which point the solution immediately turned cloudy. Upon blending, a rubbery white substance preciptated out of solution and stuck to my stick blender and the sidewalls of the beaker. This was not supposed to happen!
Rubbery goop on the blender head
Precipitate at the bottom of the beaker
I tried everything I could think of - diluting the triethanolamine and adding it slowly to reduce sudden pH changes, lowering the alcohol concentration, and even letting the carbomer sit in solution for a few days before adding the triethanolamine. Nothing worked. I went back to square one and started reading more papers and watching process demonstration videos from the manufacturer. Eventually I noticed one source that suggested increasing the pH of the water to about 8 *before* adding the carbomer. This worked and gave a beautiful clear gel!
After a bit of tinkering I found a good process: Starting with 100 ml of water, titrate to pH 8 with triethanolamine. Add 1 g of carbomer powder and blend until fully gelled. Add 300 ml of reagent alcohol a bit at a time, mixing thoroughly after each addition. About halfway through adding the alcohol the gel started to get pretty runny so I mixed in a few more drops of triethanolamine and another 500 mg of carbomer powder before mixing in the rest of the alcohol. I had only a little more alcohol left in the bottle (maybe 50 ml) so I stirred that in without bothering to measure. The resulting gel was quite stiff and held its shape for a little while after pouring, but could still be transferred between containers without muich difficulty.
Tea light can full of my final fuel
I left the beaker of fuel in my garage for several days and shook it around a bit, but saw no evidence of degradation. Since it's basically just turbo-strength hand sanitizer (~78% instead of the usual 30-60%) without all of the perfumes and moisturizers, it should be pretty stable. I had no trouble igniting it down to 10C ambient temperatures, but may find it necessary to mix in some acetone or other low-flash-point fuel to light it reliably in the winter. The final batch of fuel filled two polypropylene specimen jars perfectly with just a little bit left over for a cooking test.
One of my two fuel jars
One tea light canister held 10.7 g / 0.38 oz of fuel, and I typically use two at a time, so 21.4 / 0.76 oz. One jar thus holds enough fuel for about five cook sessions, which is more than I'd ever need for a SAR mission or weekend camping trip. The final weight of my entire cooking system (stove, one fuel jar, tea light cans, and pot) comes out to 408 g / 14.41 oz, or a bit less than an empty Whisperlite stove (not counting the pot, fuel tank, or fuel)! The only thing left was to try cooking on it. I squeezed a bacon-cheddar FSR sandwich into my pot, added a bit of water, and put it on top of the stove with two candle cups of fuel.
Nice clean blue flame, barely visible
By the six-minute mark the water was boiling away merrily and a cloud of steam was coming up around the edge of the lid. I took the pot off around 8 minutes and removed my snack.
Munching on my sandwich. You can't tell in this lighting, but the stove is still burning.
For those of you who haven't eaten First Strike Rations, the sandwiches in them are kind of like Hot Pockets or Toaster Strudels, except with a very thick and dense bread rather than a fluffy, flaky one. The fats in the bread are solid at room temperature and liquefy once it gets warm. This significantly softens the texture of the bread and makes it taste a lot better, so reaching this point is generally the primary goal when cooking one. My sandwich was firmly over that line and tasted very good (for Army food baked two years ago). The bacon could have been a bit warmer, but the stove kept on burning until a bit after the ten-minute mark so I could easily have left it in the boiling water for another two minutes and made it even hotter.
Once I was done eating it was time to clean up. The stove had no visible dirt (beyond what was there from my previous experiments), and the tea light canisters were clean and fairly free of soot except in one or two spots around the edges. Almost no goopy residue was left behind.
Stove after the cook test
The pot was quite clean as well, with no black soot and only a very thin film of discoloration that was thin enough to leave colored interference fringes. Some of this was left over from previous testing, so if this test had been run on a virgin pot there'd be even less residue.
Bottom of the pot after the cook test
Overall, it was a long journey with many false steps, but I now have the ability to cook for myself over a weekend trip in less than a pound of weight, so I'm pretty happy.
EDIT: A few people have asked to see the raw data from my temperature-vs-time cook tests, so here it is.